
专名挖掘
通过词语间语义相关性计算寻找人名、地名、机构名等词的相关词,扩大专有名词的词典,更好的辅助应用
功能介绍
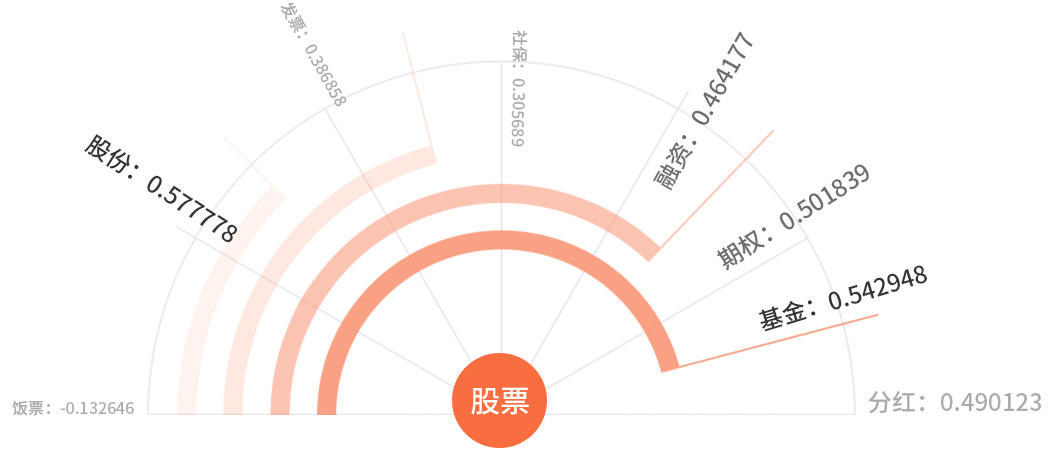
本技术用于计算两个给定词语的语义相似度,基于自然语言中的分布假设,即越是经常共同出现的词之间的相似度越高。
词义相似度是自然语言处理中的重要基础技术,是专名挖掘、query改写、词性标注等常用技术的基础之一
应用场景

专名挖掘

query改写
技术特色

词表覆盖广
深度学习训练

描述精度高
